IRCAM, 1 place Igor-Stravinsky, 75004 Paris, France. Espaces Nouveaux, 56 Boulevard Davout, 75020 Paris, France. Tel: (+33) 01 44 78 15 17. Fax: (+33) 01 44 78 15 40. E-Mail: jmjot@ircam.fr
(*) This paper is a revision, written in October 1996, of a paper presented
at the 5th International Conference "Interface to real and virtual worlds"
(Montpellier, France) in May 1996, initially entitled "Synthesizing
three-dimensional sound scenes in audio or multimedia production and interactive
human-computer interfaces".
Abstract
This paper overviews the principles and techniques for synthesizing three-dimensional sound scenes with application to audio and multimedia production or multimodal human-computer interfaces (e.g. virtual reality). A real-time spatial sound processing software, the Spatialisateur, is presented. It allows to reproduce and control the localization of sound sources in three dimensions as well as the reverberation of sounds in an existing or virtual space. A particular aim of the Spatialisateur project is to provide direct control over the perceptually-relevant spatial attributes associated to each sound source and to the virtual space, while allowing reproduction via various systems or formats over loudspeakers or headphones. The advantages of this approach are illustrated in practical contexts.
1. Introduction
1.1. Aims of spatial sound reproduction
The reproduction of complex sound scenes including multiple sources at different positions in an existing or imaginary space has long been a major concern in professional recording and production of music and soundtracks. More recently, the evolution of computer technology has led to the development of "virtual reality" systems aiming at immersing an individual in an artificial scene through the reconstruction of multisensorial cues (particularly auditory, visual and haptic cues).
From an auditory point of view, the spatial cues to be reproduced can be divided into two categories: the auditory localization of sound sources (desirably in three dimensions), and the room effect resulting from indirect sound paths (reflections and reverberation from walls and obstacles). The benefits of spatial sound reproduction over mono reproduction are significant in a wide range of artistic, research, entertainment and industrial applications. These include professional audio and computer music, teleconferencing, simulation and virtual reality, telerobotics, and advanced machine interfaces for data representation or visually disabled users.
Spatial sound processing is a key factor for improving the legibility and naturalness of a virtual scene, restoring the ability for our perception to exploit spatial auditory cues in order to segregate sounds emanating from different directions [Blauert 1983, Begault 1994]. It further allows manipulating the spatial attributes of sound events for creative purposes or "augmented reality" [Cohen & Wenzel 1995]. However, as a general rule, the perceptual effect and the realism of the reproduced auditory cues are likely to be influenced by their degree of coherence with concurrent visual or cognitive cues (or, as well, by the absence of such concurrent cues).
1.2. Basic principles of spatial sound reproduction
Spatial sound reproduction requires an electro-acoustic system (loudspeakers or headphones) which must be adapted to the context of application (concert performance, domestic hi-fi installation, computer display, individual head-mounted display, etc...). In association with this system, a technique or format must be defined for encoding directional localization cues on several audio channels for transmission or storage. A spatially encoded sound signal can be produced by two complementary approaches:
a) Recording an existing sound scene with a coincident or closely-spaced microphone system (located essentially at the virtual position of the listener within the scene). This could be e.g. a stereo microphone pair, a dummy head, a "Soundfield" microphone... Such a sound pickup technique can simultaneously encode all spatial auditory cues associated to the different sound sources in the scene, as perceived from a given position. However, this approach considerably limits the possibilities of future manipulations of the relative positions of the sources, modifications of room reverberation or adaptation to various reproduction setups or listening rooms.
b) Synthesizing a virtual sound scene: the localization of each sound source and the room effect are artificially reconstructed by use of an electronic signal processing system. This system receives individual source signals and provides a control interface for describing the sound scene. The control parameters might include the position, orientation, and directivity of each source, along with an acoustic characterization of the virtual room or space. A typical example of this approach, taken from the field of professional audio, is the post-processing of a multi-track recording using a stereo mixing console and peripherals such as artificial reverberators.
In an interactive application where elements of the sound scene can be dynamically modified by the user's or performer's actions (e.g. tracking movements of the sound sources or the listener), it is necessary to reconstruct a virtual sound scene and update the control parameters in real time. This requires local signal processing resources within the audio display system, and involves a processing complexity which increases linearly with the number of sound events to be synthesized simultaneously. From a general point of view, the spatial synthesis parameters can be provided either by the user's actions (man-to-machine interface: mixing desk, graphic or gestual interface...), by a stand-alone process (sequencer, simulator, videogame...), or by the analysis of an existing scene (via magnetic or ultrasound position trackers, cameras, etc...).
The spatial synthesis technique can be designed to simulate the directional encoding characteristics of a given microphone pickup technique. This will ensure a compatibility allowing to combine the two approaches (a) and (b) described above. The digital computations involved in reproducing a realistic sound scene can thus be minimized, for instance, by performing real-time spatial processing of a limited number of source signals, and mixing the processed signals with an "ambiance" recorded by a microphone system in an real scene. When a recording made with a stereo microphone pair is to be mixed with monophonic signals recorded separately, the mixing console's panoramic potentiometers ("panpots") should, ideally, simulate the directional encoding characteristics of that stereo microphone system, in order to optimize the naturalness and coherence of the final mix (this is hardly ever possible, however, with current mixing consoles).
In the next section of this paper, the general principles and limitations of current spatial sound processing and room simulation technologies will be reviewed. In the third section, a perceptually-based processor, the Spatialisateur, will be introduced. In conclusion, the advantages and applications of this approach will be illustrated in practical contexts.
2. An overview of current 3-D sound processing techniques
2.1. The basic mixing architecture
In a natural situation, directional localization cues (perceived azimuth and elevation of a sound source) are typically conveyed by the direct sound path from the source to the listener. However, the intensity of this direct sound is not a reliable distance cue in the absence of a room effect, especially in an electro-acoustically reproduced sound scene [Blauert 1983, Begault 1994]. Thus the typical mixing structure shown on Figure 1 defines the minimum signal processing system for conveying three-dimensional localization cues simultaneously for M sound sources over P loudspeakers.
Each channel of the mixing console receives a monophonic recorded or synthetic signal (preferably devoid of room effect) from an individual sound source, and contains a panning module which synthesizes directional localization over P output channels (this module is usually called a panoramic potentiometer, or "panpot", in stereo mixing consoles). The role of the panning module is to encode the acoustic information conveyed by a sound coming from a given direction in free field (i.e. in an anechoic environment). In addition, via an auxiliary bus, all source signals feed an artificial reverberator which delivers several uncorrelated signals to the output channels, thus reproducing a diffuse (multi-directional) room effect to which every sound source can contribute a different intensity. The relative values of the gains d and r can be adjusted in each channel in order to control the perceived distance of the corresponding sound source. This system allows to create for a listener the illusion that the sound sources are located at different positions in the same room.
This basic principle of current mixing architectures, usually designed to produce a conventional 2-channel stereo output, can readily be extended to multi-channel loudspeaker layouts in two or three dimensions. This essentially requires that an appropriate "panpot" be designed for a given loudspeaker layout. In the 1970's, Chowning designed a spatial processing system for computer music, which had an architecture similar to Figure 1 [Chowning 1971]. This system allowed bidimensional control of the localization and movements of virtual sound sources over four loudspeakers. The localization of each source was parametrized using polar coordinates (distance and azimuth angle in the horizontal plane) referenced to the center of the loudspeaker layout.
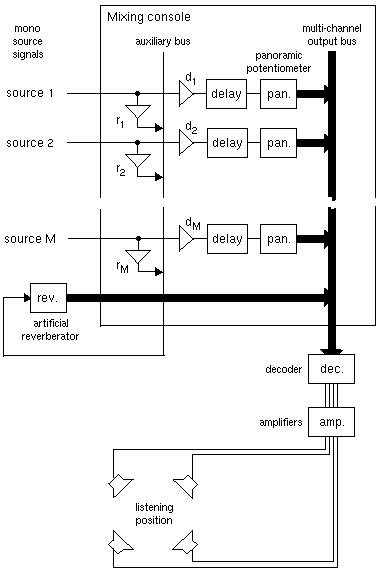
Typical mixing architecture (here assuming 4-channel loudspeaker reproduction) combining a mixing console allowing to control the directional effects and an external reverberation unit for synthesizing the temporal effects. Recent digital mixing consoles include a tunable delay line in each channel. An output decoding stage may be necessary, with some spatial encoding techniques, before delivering the mixed signal to the loudspeakers.
2.2. Directional panning over loudspeakersTo reproduce the direction of each sound source over four loudspeakers, Chowning used a pairwise intensity panning technique (often referred to as "discrete surround"), derived from the conventional stereo panning module [Chowning 1971, Theile & Plenge 1977]. More generally, the current techniques for directional panning of sounds in two or three dimensions using a reasonably limited number of loudspeakers are based on one of the following two approaches: - Some extension of the "discrete surround" panning technique, this approach being characterized by the fact that only a limited number of neighboring loudspeakers will be used for reproducing a given direction (except possibly for reproducing sounds located closer than the loudspeakers); - Simulation of the directional encoding characteristics of some arrangement of coincident or closely-spaced microphones. This can be applied to any spatial sound pickup system, including conventional stereo recording techniques, binaural (dummy head) recording, and the 4-channel Ambisonic "B format" (as produced by a Soundfield microphone). As mentioned earlier, this approach will offer the benefit of straightforward mixing compatibility with an actual recording made in an existing situation according to the same pickup technique.
Unlike conventional 2-channel stereo recording formats, the B format comprises 4 channels allowing to encode front-back and up-down cues, in addition to left-right cues and an omnidirectional pressure information. For reproduction over loudspeakers, a B-format recording must be processed through an "Ambisonic" decoder. Such decoders are commercially available and can accommodate various multi-channel loudspeaker layouts of typically 4 to 8 loudspeakers [Gerzon 1985, Gerzon 1992]. Similarly, as described in the next section, a binaural recording should be processed through a "transaural" decoder in order to provide faithful three-dimensional reproduction over loudspeakers [Cooper & Bauck 1989].
In practice, all of the above panning techniques assume that the listener is located at a specific position with respect to the loudspeakers. Whatever the approach adopted, some degradation of the auditory illusion must be expected for a non-centrally located listener. However, the type and annoyance of the degradation will depend on the technique used and on the listening conditions (particularly the number of loudspeaker channels, the dimensions of the loudspeaker layout and the size of the listening area). The consequence for the musician or sound engineer is that, for each particular listening situation with loudspeakers, a selection should be made among the possible three-dimensional encoding approaches (discrete surround, Ambisonics, or transaural).
The audio industry has not succeeded in establishing a three-dimensional encoding format satisfying a wide range of 3D sound applications. The current widespread industry standards, if one excepts Ambisonics and its derivatives, provide multichannel transmission / storage formats directly related to recommended loudspeaker layouts, leaving the choice of the encoding technique to the program producer. Matrixing methods allowing to encode a 4-channel recording over two transmission / storage channels (such as Dolby stereo) do not perform a directional encoding function. In an attempt to overcome some of the limitations of the conventional two-channel transmission format and address HDTV, multimedia and domestic entertainment applications, a "3/2-stereo" standard has been proposed [Theile 1993]. The 3/2-stereo format provides an additional "center" channel in order to stabilize frontal sounds, as well as two "surround" channels which are intended to feed lateral or rear loudspeakers (left and right), essentially for reproducing diffuse ambiance and reverberation. This format implies a forward bias for the localization of primary sound sources in the reproduced scene, and does not allow precisely controlled localization of lateral, rear or elevated sound sources.
2.3. Binaural and transaural processing
The binaural encoding format has the property of allowing three-dimensional encoding of sounds (including elevation) over two channels only. A binaural recording (made with a dummy head or with two miniature microphones inserted in the ear canals of an individual) can rightfully be expected to provide exact spatial sound reproduction over headphones, since this technique will directly reproduce the pressure signals at the two ears (provided that proper care is taken in equalizing the frequency response of the headphones used for playback).
The binaural panning module can be implemented in the digital domain as illustrated on Figure 2. By use of a dummy-head and a loudspeaker in an anechoic room, a set of "head-related transfer functions" (HRTFs) can be measured, subsequently allowing to simulate any particular direction of incidence of a sound wave in free field (i.e. without acoustic reflections) [Blauert 1983, Begault 1994].
Principle of binaural synthesis, simulating a free-field (i.e. anechoic) listening situation over headphones. The direction of the virtual sound source (azimuth and elevation) is reproduced by a pair of digital filters whose coefficients are loaded from a database of "Head Related Transfer Functions" (HRTFs). These transfer functions can be measured in an anechoic room by use of a loudspeaker and a dummy head (or two miniature microphones inserted in the ear canals of an individual).
Early binaural processors and binaural mixing consoles, developed in the late 1980's [Persterer 1989], used powerful signal processors in order to accurately implement the HRTF filters in real time. Further research on the modeling of HRTFs has led to efficient implementations of time-varying HRTF filters allowing to simulate dynamic movements of sound sources [Begault 1994, Foster & al. 1991, Jot & al. 1995]. A dynamic implementation approximately involves twice the computational cost of a static implementation. Thus, with current programmable digital signal processors (such as the Motorola DSP56002 or Texas Instruments TMS320C40), a straightforward implementation of a variable binaural panpot using 200-tap convolution filters would require the signal processing capacity of two DSPs at a sample rate of 48 kHz. This cost can be reduced to less than 150 multiply-accumulates per sample period (30% of the capacity of one DSP) using an implementation based on minimum-phase pole-zero filters and variable delay lines [Jot & al. 1995].Because the HRTFs actually encode diffraction effects which depend essentially on the morphology of the head and pinnae, the applicability of binaural technology in broadcasting and recording is limited by the individual nature of the HRTFs. In order to ensure perfect reproduction over headphones, it would be necessary to perform HRTF measurements for each listener. A typical consequence of using non-individual HRTFs is the difficulty of reproducing virtual sound sources localized in the frontal sector over headphones (these will often be heard above or behind, near or even inside the head) [Begault 1994]. An additional constraint with headphone reproduction is that it calls for the use of a head-tracking system in order to compensate for listener movements in real-time within the binaural synthesis process. In the framework of interactive applications such as virtual reality, binaural synthesis then offers an attractive solution because the dynamic localization cues conveyed by head-tracking can compensate the ambiguities resulting from the use of non-individual HRTFs.
In order to preserve the three-dimensional localization cues in reproduction over a pair of loudspeakers, a binaural signal must be decoded through a 2 x 2 inverse matrix transfer function which has the effect of canceling the cross-talk from each loudspeaker to the contralateral ear [Cooper & Bauck 1989]. Although this technique assumes a strong constraint on the position and orientation of the loudspeakers and the listener's head during playback, it is a viable approach in broadcasting and recording applications over two channels. Experience shows that, with a carefully installed listening setup (in the conventional stereophonic layout), transaural stereophony can produce reliable localization cues outside of the frontal sector delimited by the two loudspeakers, although there remains a degree of uncertainty for virtual sound sources located in the rear sector or above the listener. On a less carefully installed hi-fi system, the performance is typically reduced to that of conventional stereophony (although a sense of depth will be preserved if room reverberation is also rendered through the transaural decoding matrix). Current research towards improved transaural reproduction includes the combination of transaural reproduction with head-tracking [Casey & al. 1995] or multichannel extensions of the technique, involving least-squares optimization over a set of listening positions [Bauck & Cooper 1992].
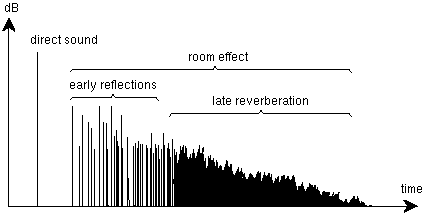
2.4. Artificial reverberators Early digital reverberation algorithms based on digital delay lines with feedback, following Schroeder's pioneering studies [Schroeder 1962], evolved into more sophisticated designs during the 1980's, allowing to shape the early reflection pattern and simulate the later diffuse reverberation more naturally and accurately [Moorer 1979, Stautner & Puckette 1982, Kendall & al. 1986, Griesinger 1989, Jot & Chaigne 1991]. An artificial reverberation algorithm based on a feedback delay network, such as shown on Figure 3, can mimic the reverberation decay characteristics of an existing room and deliver several uncorrelated channels of natural-sounding reverberation, while using only a fraction of the processing capacity of a typical programmable DSP [Jot 1995, Jot 1992].
Another approach to real-time artificial reverberation was developed recently, based on hybrid convolution in the time and frequency domain [Gardner 1995, Reilly & McGrath 1995]. Unlike earlier convolution algorithms, these hybrid algorithms allow implementing a very long convolution filter with no input-output delay for an affordable computational cost. Convolution processing allows exact reproduction of reverberation on the basis of an impulse response measured in an existing room or derived from a computer model. However, it is impractical to dynamically update the lengthy impulse response in a convolution processor in order to tune the artificial reverberation effect or simulate moving sound sources. In most interactive applications, this convolution approach must be restricted to the rendering of the late reverberation (which can be synthesized more efficiently by a feedback delay network as described above).
When using a reverberation unit in combination with a conventional mixing console, the musician or sound engineer faces a less-than-ideal user interface: the perceived distance of sound sources cannot be controlled effectively using only the gain controls d and r in each channel of the mixing console (see Figure 1), because the effect will largely depend on the settings of the reverberator's controls. This heterogeneity of the user interface limits the possibilities of continuous modification of the perceived distance of the virtual sound sources. Furthermore, in most current reverberation units, intuitive adjustments of the room effect are typically limited to the modification of the decay time or the size of a factory-preset virtual room, and the signal processing structure is usually not designed for reproduction formats other than conventional stereophony. These limitations make traditional mixing environments inadequate for interactive and immersive applications, as well as broadcasting and production of recordings in B format or recent multichannel formats such as 3/2-stereo.
2.5. Dynamic distance and room effect control in interactive applications In order to provide more efficient control over the positions and movements of sounds, Chowning's initial design provided a distance control which simultaneously affected the gains d and r in the mixing architecture of Figure 1: the intensity of the direct sound followed the natural inverse squared distance law, while the intensity of the reverberation followed an inverse distance law [Chowning 1971]. In order to reinforce the perception of direction of the sound source for large distances, a fraction of the reverberation signal was directional (coming from the same direction as the direct sound). In addition, the system included a pitch-shifting technique in order to simulate Doppler effects accompanying dynamic variations of the distance.
However, this basic mixing architecture (Figure 1) does not allow to faithfully reproduce the perception of sound sources as experienced in a particular natural environment, because the temporal and directional distribution of early reflections can not be controlled specifically for each virtual sound source. Overcoming this limitation implies providing not only a panpot in each channel of the mixing environment, but also an independent early reflection module, as shown on Figure 4. Moore [Moore 1982] proposed a signal processing architecture allowing to control the amplitudes and time delays of the first reflections, for each source signal and each output channel, according to: - the position, directivity and orientation of each virtual sound source, - the geometry of the virtual room and the absorption characteristics of the air and walls, - the geometry of the loudspeaker system.
The general processing model proposed by Moore for concert performances consists of a polygonal 'listening' room delimited by the loudspeaker positions and containing the audience, inserted in a larger room (the 'virtual' room) containing the virtual sound sources. The signals delivered to the loudspeakers are reconstructions of the signals captured by P virtual microphones located along the exterior perimeter of the 'listening' room, at the positions of the P loudspeakers.
Typical schematic echogram for a source and a receiver in a room, and cost-efficient real-time binaural room simulation algorithm based on a feedback delay network. The delay lengths ti and gains bi allow controlling the time, amplitude and lateralization of each early reflection. The feedback matrix A is a unitary (energy preserving) matrix, and the feedback delay lines incorporate attenuation filters designed to provide accurate tuning of the reverberation decay time vs. frequency. In a typical implementation of this algorithm, the number N of feedback channels ranges from 8 to 12.
Improved mixing architecture allowing to reproduce several virtual sound sources located in the same virtual room while controlling the early reflection pattern associated to each individual source [Moore 1982, Jot 1992].
Moore´s directional encoding method for loudspeaker reproduction simulates a multi-microphone recording using a non-coincident microphone system, according to the principles described in section 2.2, although the microphones are much more spaced than in conventional recording techniques. The identification of indirect sound paths from each source to each virtual microphone is based on a geometrical simulation of sound propagation assuming specular reflections of sound waves on the walls of the virtual room (according to the image source model). The arrival time and frequency-dependent attenuation of each early reflection can be computed by simulating all physical phenomena along the corresponding sound path as a cascade of elementary filters (taking into account the directivities of the source and the microphone, as well as absorption by propagation through the air and by reflections on the walls). Moore deals with the particular case of headphone reproduction by reducing the size of the 'listening room' to the size of a head, and placing the two microphones on its sides. The directional encoding model then becomes equivalent to a rough implementation of the "binaural panpot" described in section 2.3., and can be readily extended in order to simulate HRTF filtering more accurately, as proposed in [Persterer 1989, Foster & al. 1991, Jot 1992].The signal processing structure underlying this physical modeling approach is similar to the basic mixing architecture of Figure 1, except that one source signal must be fed to several channels of the mixing console so that each additional channel reproduces one early reflection. The delay and gain can be adjusted in each channel to control the arrival time and amplitude of the reflection (as captured by an omnidirectional microphone placed at the reference listening position) and the panning module then derives P signals in order to encode the direction of incidence of the reflection.
Recently, digital audio processors performing binaural processing of both the direct sound and several early reflections in real time have been proposed, where room reflection parameters are computed according to the image source model [Persterer 1989, Foster & al. 1991]. Such processors involve a heavy real-time signal processing effort, since a binaural panning module must be affected to each early reflection and for each virtual sound source. To synthesize in real time a typical sound scene containing several sources, this implies a minimum number of about 30 to 50 binaural panpots, which is impractical for most real-world applications. In addition to this signal processing task, a considerable processing effort is necessary for updating all reflection parameters dynamically whenever a sound source is displaced or the listener moves. As Moore noted, these parameters should be tracked fast enough to allow smooth dynamic variation of the delay times, and thus produce the natural Doppler effects (both on the direct sound component and on each early reflection).
The overall processing complexity makes this exhaustive approach impractical unless it is limited to particularly simple geometries (such as rectangular rooms), a small number of source signals and a small number of early reflections per source. However, the signal processing cost can be substantially reduced by introducing perceptually relevant simplifications in the spectral and binaural processing of early reflections [Jot & al. 1993, Jot & al. 1995]. Furthermore, the computational effort involved in the dynamic tracking of reverberation parameters can be drastically reduced on the basis of a perceptual control paradigm, as described in the following of this paper.
3. Perceptually-based spatial sound processing In many applications involving real-time spatial sound processing, the algorithms used for synthesizing the room effect need not reproduce the exact response of an existing room in a given situation, or the physical propagation of sound in rooms. Reference to the physics of the reverberation process should not be imposed on the user as a consequence of the technique implemented for synthesizing the room effect (although some statistical properties of room reverberation are indeed relevant to the design of a natural-sounding artificial reverberation algorithm [Schroeder 1962, Jot 1992]).
On the other hand, the following features are desirable in a spatial reverberation processor:
Tunability, in real time, through perceptually relevant control parameters:
The control parameters should include the azimuth and elevation of each virtual
sound source, as well as descriptors of the room effect, separately for each
source. The perceptual effect of each control parameter should be predictable and
independent of the setting of other parameters. A measurement and analysis
procedure should allow to automatically derive the settings of all control
parameters for simulating an existing situation.
Configurability according to the reproduction setup and context: Since there is no single encoding or reproduction format that can satisfy all 3-D sound applications, it should be possible, given a specification of the desired localization and reverberation effects, to configure the signal processor in order to allow reproduction of these effects in various formats over headphones or loudspeakers. This should include corrections (equalization) in order to preserve the perceived effect, as much as possible, between different setups and different listening rooms.
Computational efficiency:
The processor should make optimal use of the available computational resources.
It should be possible, considering a particular application where the user or the
designer can accept a loss of flexibility or independence between some control
parameters, to further reduce the overall complexity and cost of the system, by
introducing relevant simplifications in the signal processing and control
architecture. One illustration is the system of Figure 4, where the late
reverberation algorithm is shared between several sources, assuming that these
are located in the same virtual room, while an independent early reflection
module is associated to each individual sound source.
3.1. The Spatialisateur
Espaces Nouveaux and Ircam have developed since 1992 a spatial sound processing
software, the Spatialisateur (a.k.a. Spat), which incorporates earlier research
on the perceptual characterization of room acoustical quality and on artificial
reverberation and spatial processing of sounds [Jullien & al. 1992, Bloch & al.
1992, Jot 1992]. The Spat software was developed in the Max / FTS object-oriented
signal processing environment, and runs in real-time on the hardware platforms
supported by the Ircam Music Workstation [Puckette 1991, Déchelle & De
Cecco 1995] (at the time of this writing, the supported platforms include NeXT
workstations equipped with ISPW plug-in boards, and Silicon Graphics
workstations).
Spat appears as a library of signal processing and control interface modules (or
objects) for real-time spatial processing of sounds. The elementary modules
include panpots, artificial reverberators, parametric equalizers... The signal
processing operations for reconstructing localization and room effect cues
associated to one source signal can be integrated in a single compact processor
(a Max object named Spat). Several processors can be associated in parallel in
order to process several source signals simultaneously, and each processor can be
easily configured according to a chosen encoding format or loudspeaker layout.
In the first version of the Spatialisateur software (Spat-0.1), released in March
1995, several directional encoding modules were designed, accommodating various
horizontal loudspeaker layouts (typically comprising 4 to 8 loudspeakers and
appropriate for small or medium-sized listening rooms and auditoria). These
designs were based solely on the discrete intensity panning technique. Since
then, new panning modules have been included in order to allow three-dimensional
encoding on two channels for personal listening over headphones or loudspeakers
(binaural or transaural reproduction), and for reproduction over
three-dimensional multichannel loudspeaker layouts.
The design approach adopted in the Spatialisateur project focuses on giving the
user the possibility of specifying the desired effect from the point of view of
the listener, rather than from the point of view of the technological apparatus
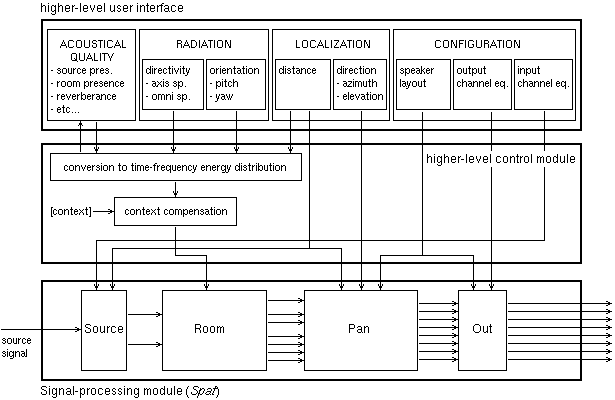
or physical process which generates that effect. A higher-level user interface
controls the different signal processing sub-modules of a Spat processor
simultaneously, and allows specifying the reproduced effect, for one source
signal, through a set of control parameters whose definitions do not depend on
the chosen reproduction format or setup (Figure 5). These parameters include the
azimuth and elevation of the virtual sound source, as well as descriptors of the
room acoustical quality (room effect) associated to the sound source.
The room acoustical quality is not controlled on the basis of a model of the
geometry and wall materials of the virtual room, but via a formalism directly
related to the perception of the reproduced sound event by the listener,
involving a small set of mutually independent "perceptual factors":
- Source perception: source presence, brilliance and warmth (energy and spectrum
of direct sound and early reflections).
- Source / room interaction: envelopment and room presence (relative energies of
direct sound, early and late room effect), running reverberance (early decay
time).
- Room perception: late reverberance (late decay time), heaviness and liveness
(variation of late decay time with frequency).
The definition of these perceptual factors is derived from psycho-experimental research carried out at Ircam on the perceptual characterization of room acoustical quality in concert halls, opera houses and auditoria [Jullien & al. 1992, Jullien 1995]. In the graphic user interface shown on Figure 5, each slider is scaled according to the average sensitivity of listeners with respect to the perceptual factor it controls, and each perceptual factor is related to a measurable acoustical index characterizing the sound transformation. These relations are implemented in the Spatialisateur's perceptual control module in order to map this representation of room acoustical quality into low-level signal processing parameters. Some of these acoustical indexes are similar to well-established indexes used for characterizing concert hall acoustics (although not explicitly implemented in current commercial reverberation units), such as the envelopment or the early decay time. The unicity of the particular set of indexes used in the Spatialisateur follows from an attempt to provide an exhaustive characterization of room acoustical quality through a minimal set of mutually independent parameters. These indexes can be computed from an impulse response measured in an existing room, which allows setting the Spatialisateur´s controls in order to mimic a real situation. Consequently, virtual and real acoustical qualities can be manipulated within a unified framework.
3.2. User interface: physical vs. perceptual approach
The synthesis of a virtual sound scene relies on a description of the positions and orientations of the sound sources and the acoustical characteristics of the space. This description is then translated into parameters of a signal processing algorithm. From a general point of view, the space could be described either by a physical and geometrical model, or by a set of attributes describing the perceived acoustical quality associated to each sound source [Jullien & Warusfel 1994]. The first approach typically suggests a graphic user interface representing the room geometry and the positions of the sources and listener, and relies on a computer algorithm simulating the propagation of sound in rooms (such as the image source model mentioned earlier). The second approach relies on a model of the perception of room acoustical quality, suggesting a graphic user interface including sliders such as shown on Figure 5, and providing a basis for a wide range of multidimensional control interfaces (this will be developed further in section 4).
A physically-based user interface will not allow to control directly and effectively the sensation perceived by the listener [Jullien & Warusfel 1994]. Although localization is naturally specified via a geometrical user interface, many aspects of room acoustical quality (such as envelopment or early reverberance) will be affected by a change in the position of the source or the listener, in a manner that is not easily predictable and depends on room geometry and wall absorption characteristics. On the other hand, adjustments of the room acoustical quality can only be achieved by modifying these geometry and absorption parameters, and the effects of such adjustments are often unpredictable or imperceptible. Additionally, a physically-based user interface will only allow the reproduction of physically realizable situations: source positions will be constrained by the geometry of the space and, even if the modeled room is imaginary, the laws of physics will limit the range of realizable acoustical qualities. For instance, in a room of a given shape, modifying wall absorption coefficients in order to obtain a longer reverberation decay will cause an increase in the reverberation level at the same time.
In contrast to a physical approach, a perceptual approach leads to a more intuitive and effective user interface because the control parameters are directly related to audible sensations. Additionally, a perceptually based specification of the room effect essentially prescribes a time-frequency energy distribution in the impulse response, which can be efficiently mapped to the signal-processing parameters of an artificial reverberation algorithm. Furthermore, the specification in terms of energy distribution leaves some degrees of freedom in the definition of the microscopic structure of the impulse response, allowing perceptually relevant simplifications in the implementation of the signal processing module (provided that the criteria are satisfied for ensuring the naturalness of the artificial reverberation). Thus, a perceptual approach yields a more efficient implementation of both the signal processing module itself and the control process which dynamically updates the low-level signal processing parameters according to the higher-level user-interface settings.
3.3. Signal processing modules
The modularity of the Spat software makes it possible to configure a spatial processing architecture according to various applications or with different computational costs, depending on the reproduction format or setup, the desired flexibility in controlling the room effect, and the available computational resources. As Shown in Figure 5, a Spat processor can be formed by cascade connection of four configurable sub-modules: Source, Room, Pan, Out. Configuring a Spat module is done in a straightforward way by calling the appropriate versions of these sub-modules.
Artificial reverberation modules
The Room module is a computationally efficient multi-channel reverberator based on a feedback delay network, and designed to ensure the necessary degree of naturalness and accuracy for professional audio or virtual reality applications [Jot 1992, Jot & al. 1995]. The input signal (assumed devoid of reverberation) can be pre-processed by the Source module, which can include a variable low-pass filter and a variable delay line to reproduce the air absorption and Doppler effects, as well as spectral equalizers allowing additional corrections according to the nature of the input signal. The Room module can itself be broken down to elementary reverberation modules (e.g. an early reflection module or a late reverberation module) which allows building a variety of mixing architectures such as those of Figure 1 or Figure 4. The reverberation modules are provided in several versions differing in complexity (number of feedback or feedforward channels), so that computational efficiency can be traded off for time or frequency density of the synthetic reverberation [Jot 1992, Jot & Chaigne 1991].
Directional encoding modules
The multichannel output format of the Room module is directly compatible with reproduction of frontal sounds in the 3/2-stereo format, and comprises 7 channels: a 'center' channel conveying the direct sound component, a 'left' and 'right' pair of channels conveying the early reflections, and four uncorrelated 'surround' channels conveying the diffuse reverberation. The output of the Room module can optionally be post-processed by the directional distribution module Pan, a 7 x P matrix which converts the above '3/4-stereo' format to the directional encoding format chosen by the user, and simultaneously encodes the perceived direction of the sound event.
The Pan module can be configured for
the following encoding formats:
- discrete surround (intensity panning) over various 2-D or 3-D loudspeaker
layouts typically comprising 4 to 8 channels (the structure of the Pan module can
be easily extended to a higher number of channels if necessary).
- binaural encoding for 3-D sound reproduction over headphones (which can be
further decoded for transaural reproduction over loudspeakers)
- B-format encoding (which can be further decoded to allow reproduction over
various 2-D or 3-D loudspeaker layouts)
- conventional two-channel stereophony (simulating various coincident or
non-coincident techniques such as MS, XY, AB, etc...);
Adaptation to the listening conditions
The reproduced effect can be specified perceptually in the higher-level control interface, irrespective of the reproduction context, and this effect is, as much as possible, preserved from one reproduction mode or listening room to another. The optional Out module can be used as a "decoder" for adapting the output of the Pan module to the geometry and acoustical response of the loudspeaker system: it can be configured to provide spectral and time delay correction (in each output channel), perform binaural to transaural format conversion (cross-talk canceling), or decode a B-format signal for listening over loudspeakers. In a mixing application, only one Out module will generally be necessary (as illustrated by the placement of the 'decoder' in Figure 1 or Figure 4).
In a typical multichannel reproduction setup, the Out module is used for equalizing the direct path from each loudspeaker to a reference listening position, without attempting to compensate for the effects of the reflections and reverberation in the listening room. However, in order to correct for the temporal and spectral effects of listening room acoustics, the high-level control processing module includes a "context compensation" algorithm which automatically adjusts the control parameters of the Room module, so that the perceived effect at a reference listening position be as close as possible to the specification given via the higher-level user interface (Figure 5). The originality of this compensation algorithm lies in that it is based on a deconvolution of the energy distribution in the impulse response (instead of the more traditional amplitude deconvolution method).
This compensation of listening room reverberation by 'echogram deconvolution' does not allow exact signal reconstruction of a given impulse response at a given listening position, and suffers from the general limitation that the desired virtual acoustical quality should be sufficiently reverberant compared to the actual listening conditions. However, unlike the amplitude deconvolution method, this approach does not involve a prohibitive constraint on the listener's position, and yields an efficient real-time compensation process allowing, for instance, to reproduce the perceived acoustical quality of a given room in another one, with recorded or live source signals.
4. Applications and perspectives
4.1. Signal processing architectures for professional audio or interactive multimodal interfaces
Even in a computationally demanding reproduction format such as binaural or transaural stereophony, a full implementation of a Spat processor requires less than 400 multiply-accumulates per sample period at a rate of 48 kHz (i.e. about 20 million operations per second) [Jot & al. 1995]. This can be handled by a single programmable digital signal processor (such as the Motorola DSP56002 or Texas Instruments TMS320C40). It is thus economically viable to insert a full spatial processor (performing both directional panning and artificial reverberation) in each channel of a digital mixing environment, by devoting one DSP to each source channel. More economical signal processing structures can also be designed where a single reverberation processor is shared by all source signals, with the only constraint that the late reverberation then receives the same decay time settings for all sound sources (which is natural if they are assumed to be located in the same room).
A configurable mixing console can be designed, capable of producing recordings in traditional or exotic formats, as well as currently developing industry standards: conventional two-channel stereo, three-dimensional two-channel stereo (binaural or transaural), 3/2-stereo or various multichannel 2-D or 3-D loudspeaker layouts. The increased processing capacity of this type of mixing architecture calls for a new generation of user interfaces for studio recording and computer music applications. Providing a reduced set of independent perceptual attributes for each virtual source, as discussed in this paper, seems a promising basis from the point of view of ergonomy.
Spatial sound processors for virtual reality and multimedia (video games, simulation, teleconference, etc...) also rely on a real-time mixing architecture and can benefit substantially from the reproduction of a natural-sounding room effect allowing effective control of the perceived distance of sound events. Many of these applications involve the simulation of several sources located in the same virtual space, which allows incorporating artificial reverberation efficiently. It is possible to further reduce the processing cost in applications which can accommodate a less refined reproduction or control of the room effect (e.g. in video games or "augmented reality" applications where an artificial sensation of distance must be controlled, while means for refined control of the virtual room's signature may be less necessary than in professional recording or computer music).
Binaural reproduction over headphones is particularly suited to virtual reality or multimedia applications, and can be combined with real-time image synthesis in order to immerse a spectator in a virtual environment. The Spatialisateur is designed to allow remote control through pointing or tracking devices and ensure a high degree of interactivity, with low latency and a typical localization control rate of 33 Hz (fast enough for video synchronization or operation with a head-tracking system). An alternative reproduction environment for simulators is a booth equipped with a multichannel loudspeaker system (such as the Audiosphere designed by Espaces Nouveaux). Current directions of research include modeling individual differences in HRTFs and individual equalization of binaural recordings, as well as improved techniques for multichannel reproduction over a wide listening area.
4.2. Live computer music performances and architectural acoustics
The perceptual approach adopted in the Spatialisateur project allows the composer to immediately take spatial effects into account at the early stages of the compositional process, without a prescribed reference to a particular electro-acoustical apparatus or performing space. Executing the spatial processing in real time during the concert performance allows introducing automatic corrections according to the reproduction setup and context. Localization effects, often manipulated in contemporary electro-acoustic music, can thus be more reliably preserved from one performance situation to another. Spatial reverberation processing allows more convincing illusions of remotely located virtual sound sources and helps concealing the acoustic signature of the loudspeakers, for a wider listening area. This makes it possible to improve the perceptual continuity between live sources and synthetic or pre-recorded signals, which is an important issue e.g. in the field of computer music [Warusfel 1990, Jullien & Warusfel 1994].
Consequently, a computer music work need not be written a priori for a specific number of loudspeakers in a specific geometrical layout. As an illustration, consider an electro-acoustic music piece composed in a personal studio equipped with four loudspeakers. Rather than producing a four-channel mix to be used in all subsequent concert performances, a score describing all spatial effects applied to each sound source can be recorded in a MIDI sequencer software. A new mix can then be produced automatically for a concert performance or installation using 8 loudspeaker channels, or a transaural CD recording preserving three-dimensional effects in domestic playback over two loudspeakers. This only implies reconfiguring the signal processing structure by calling adequate versions of the Pan and Out modules, and adjusting the loudspeaker layout and equalization parameters appropriately.
Spat can be used for designing an electro-acoustic system allowing to modify the acoustical quality of an existing room, for sound reinforcement or reverberation enhancement purposes, with live sources or pre-recorded signals. In the case of sound systems addressing relatively large audience areas (e.g. large concert halls or multipurpose halls), the signal processing architecture can be configured specifically (by inter-connecting sub-modules of Spat), according to a division of the audience and stage areas into adjacent zones, in order to ensure effective control of the perceptual attributes related to the temporal distribution of the direct sound and the early reflections, for the whole audience.
4.3. Musical and multidimensional interfaces
Since its initial release in 1995, Spat has been used in several musical projects and in the production of several CD recordings (using the transaural reproduction mode). At the compositional stage, the perceptual paradigm allows manipulating spatial attributes of sounds as natural extensions of the musical language. The accessibility of perceptually relevant attributes for describing the room effect can encourage the composer to manipulate room acoustical quality as a musical parameter, together with the localization of sound events [Bloch & al. 1992, Jullien & Warusfel 1994]. In one approach, initiated by Georges Bloch in 1993 with an early Spatialisateur prototype, the spatial processor's score is recorded in successive "passes" on the tracks of a sequencer. During each pass, additional manipulations of the spatial attributes of one or several sound sources can be introduced in the score (and monitored simultaneously in real-time, combined with spatial manipulations already written in the score). This is similar to operating an automation system in a mixing console, albeit allowing to manipulate a coherent set of spatial and room acoustical parameters, which is not possible in current mixing console automation systems.
In this 'automated' approach, it is critical that the control parameters be mutually independent from a perceptual point of view, i.e. that the manipulation of a spatial attribute may not destroy or modify the perceived effect of previously stored manipulations of other spatial attributes (except possibly in extreme and straightforward cases: for instance, an extremely low setting of the room presence will make adjustments of the late reverberance hardly perceptible). For operational efficiency, it is desirable that the perceived effect of each parameter be predictable, particularly when it is desired to edit the score or write it directly without real-time monitoring. As discussed earlier in this paper, such modes of operation are quite impractical within a physically-based framework, or within the traditional combination of mixing consoles and reverberation units.
Besides a sequencing or automation process, another approach for creating simultaneous variations of several spatial attributes for one or several virtual sound sources consists of mapping a subset of these perceptual attributes to the coordinates of a multidimensional graphic or gestual interface. A basic illustration of this approach is included in the higher-level user-interface of the Spatialisateur (Figure 5), allowing straightforward control of a Spat processor with a bidimensional or three-dimensional control interface delivering polar localization coordinates: the 'distance' control is mapped logarithmicly to the 'source presence' perceptual factor, with the 'drop' parameter defining the drop of the source presence in dB for a doubling of the distance (setting 'drop' to 6 dB simulates the natural attenuation of a sound with distance). A variation relevant to studio mixing is a bidimensional map of the virtual sound scene, representing the sound sources at different positions in the horizontal plane around the listener.
This mapping principle can of course be implemented in many other fashions. Because of the nature of the multidimensional scaling analysis procedure which led to the definition of the perceptual factors [Jullien & al. 1992, Jullien 1995], this set of factors forms an orthogonal system of perceptual coordinates, allowing to define a Euclidean norm measuring the perceptual dissimilarity between acoustical qualities. This implies that linear weighting along one perceptual factor or a set of perceptual factors provides a general and perceptually relevant method for interpolating between different acoustical qualities [Jullien & Warusfel 1994]. For instance, it allows implementing a gradual and natural-sounding transition from the sensation of listening to a singer 20 meters away from the balcony of an opera house to the sensation of standing 3 meters behind the singer in a cathedral (possibly based on acoustical impulse response measurements made in two existing spaces). In this example, a physically based control paradigm would require implementing an arguable geometrical and physical "morphing" process between the two situations.
These perspectives suggest the development of new multidimensional interfaces for music and audio components of virtual reality. An additional direction of research is the extension of the perceptual control formalism to spaces such as small rooms, chambers, corridors or outdoor spaces. In the current implementation of Spat, such spaces can be dealt with by manipulating, in addition to the higher-level perceptual factors, some lower-level processing parameters (accessible through the user interface of the Room module).
Acknowledgments
Spatialisateur technology is covered by issued and pending international patents. The perceptual approach adopted in this project is derived from research on the characterization of room acoustical quality directed by Jean-Pascal Jullien and Olivier Warusfel. The basic research on artificial reverberation algorithms was carried out at the Ecole Nationale Supérieure des Télécommunications in collaboration with Studer Digitec. Research on binaural synthesis and transaural processing was carried out in collaboration with the Centre National d'Etudes des Télécommunications, and includes contributions by Martine Marin and Véronique Larcher. Three-dimensional loudspeaker reproduction modules include contributions by Philippe Derogis and Alain Richon. Musical / graphical user interfaces were developed in collaboration with Georges Bloch, Tom Mays, Gerhard Eckel and Gilbert Nouno.
References
J. L. Bauck & D. H. Cooper: Generalized transaural stereo;
Proc. 93rd Conv. Audio Eng. Soc., preprint 3401, 1992.
D. Begault: 3-D Sound for virtual reality and multimedia; Academic Press,
1994.
J. Blauert: Spatial Hearing: the Psychophysics of Human Sound
Localization; MIT Press, 1983.
G. Bloch, G. Assayag, O. Warusfel, J.-P.
Jullien: Spatializer: from room acoustics to virtual acoustics; Proc.
International Computer Music Conference, 1992.
M. A. Casey., W. G. Gardner,
S. Basu: Vision steered beam-forming and transaural rendering for the artificial
life interactive video environment (ALIVE); Proc. 99th Conv. Audio Eng. Soc.,
preprint 4052, 1995.
J. Chowning: The simulation of moving sound sources; J.
Audio Eng. Soc., vol. 19, no. 1, 1971.
M. Cohen & E. Wenzel: The design of
multidimensional sound interfaces; Technical Report 95-1-004, Human Interface
Laboratory, Univ. of Aizu, 1995.
D. H. Cooper & J. L. Bauck: Prospects for
transaural recording; J. Audio Eng. Soc., Vol. 37, no. 1/2, 1989.
F.
Déchelle & M. De Cecco: The Ircam real-time platform and applications;
Proc. International Computer Music Conference, 1995. S. Foster, E. M. Wenzel, R.
M. Taylor: Real-time synthesis of complex acoustic environments; Proc. IEEE
Workshop on Applications of Digital Signal Processing to Audio and Acoustics,
1991.
W. G. Gardner: Efficient convolution without input-output delay; J.
Audio Eng. Soc., vol. 43, no. 3, 1995.
M. A. Gerzon: Ambisonics in
multichannel broadcasting and video; J. Audio Eng. Soc., vol. 33, no. 11,
1985.
M. A. Gerzon: Psychoacoustic decoders for multispeaker stereo and
surround sound; Proc. 93rd Conv. Audio Eng. Soc., preprint 3406, 1992. D.
Griesinger: Practical processors and programs for digital reverberation; Proc.
7th Audio Eng. Soc. International Conf., 1989. G. Kendall, W. Martens, D. Freed,
D. Ludwig, R. Karstens: Image-model reverberation from recirculating delays;
Proc. 81st Conv. Audio Eng. Soc., preprint 2408, 1986.
J.-M. Jot & A.
Chaigne: Digital delay networks for designing artificial reverberators; Proc.
90th Conv. Audio Eng. Soc., preprint 3030, 1991. J.-M. Jot: Etude et
réalisation d'un spatialisateur de sons par modèles physiques et
perceptifs; Doctoral dissertation, Télécom Paris, 1992.
J.-M.
Jot, O. Warusfel, E. Kahle, M. Mein: Binaural concert hall simulation in real
time; presented at the IEEE Workshop on Applications of Digital Signal Processing
to Audio and Acoustics, 1993.
J.-M. Jot, V. Larcher, O. Warusfel: Digital
signal processing issues in the context of binaural and transaural stereophony;
Proc. 98th Conv. Audio Eng. Soc., preprint 3980, 1995.
J.-P. Jullien, E.
Kahle, S. Winsberg, O. Warusfel: Some results on the objective and perceptual
characterization of room acoustical quality in both laboratory and real
environments; Proc. Institute of Acoustics, Vol. XIV, no. 2, 1992.
J.-P.
Jullien & O. Warusfel: Technologies et perception auditive de l'espace; Les
Cahiers de l'Ircam, vol. 5 "L'Espace", 1994.
J.-P. Jullien: Structured model
for the representation and the control of room acoustical quality; Proc. 15th
International Conf. on Acoustics, 1995.
F. R. Moore: A general model for
spatial processing of sounds; Computer Music J., vol. 7, no. 6, 1983.
J. A.
Moorer: About this reverberation business; Computer Music J., vol. 3, no. 2,
1979.
A. Persterer: A very high performance digital audio processing system;
Proc. 13th International Conf. on Acoustics, 1989.
M. Puckette: Combining
event and signal processing in the Max graphical programming environment;
Computer Music J., vol. 15, no. 3, 1991.
A. Reilly & D. McGrath: Convolution
processing for realistic reverberation; Proc. 98th Conv. Audio Eng. Soc.,
preprint 3977, 1995. M. R. Schroeder: Natural-sounding artificial reverberation;
J. Audio Eng. Soc., vol. 10, no. 3, 1962.
J. Stautner & M. Puckette:
Designing multi-channel reverberators; Computer Music J., vol. 6, no. 1,
1982.
G. Theile & G. Plenge: Localization of lateral phantom sources; J.
Audio Eng. Soc., vol. 25, no. 4 , 1977.
G. Thiele: The new sound format
"3/2-stereo"; Proc. 94th Conv. Audio Eng. Soc., preprint 3550a, 1993.
O.
Warusfel: Etude des paramètres liés à la prise de son pour
les applications d'acoustique virtuelle; Proc. 1rst French Congress on Acoustics,
1990.