| MAX NEUHAUS AUDIUM Radio Net was done in 1977, and shortly after finishing it I began to develop an international project which I called "Audium". I was interested in including people with different native tongues in this nonverbal dialogue. I also wanted to go further in removing myself from the actual process of the broadcasts - this idea of implementing these virtual spaces in a completely autonomous system. There were also some other new ideas which I will come to. I think of an electronic system as a special kind of statement of idea. Writing something in words on a piece of paper or making a drawing are static statements of idea. If you program an idea into a computer system, though, you not only have the written statement of the idea but the system also realizes the idea - dynamic statement of idea. I wanted to implement "Audium" in a system which would not only state the idea but execute it as well. All the previous systems had been built with analog circuitry because that was the only technology available. Here, I wanted the freedom of moving into the digital world. Unfortunately in 1980 the digital sound world was not there. I did find a very strange company in Massachusetts who made a digital signal-processing box that weighed a couple of hundred pounds; they were very curious who I was because their only other customer was the US Navy. Theoretically one could have done something with it; but it would have been starting from scratch, a decade of writing assembly-code routines. So throughout the eighties I concentrated on other things. In the beginning of the nineties I noticed that the means to realize many of my digital dreams were sitting in boxes in the music store as sound-processing and synthesis devices. There were also some computer languages around to control them in ways beyond what their manufacturers intended and envisaged. In 1990 I began collecting research material for a work called "Audium Model". The most difficult thing about realizing large new ideas is explaining what they are to those who will provide the support to realize them. You can talk about it and write about it, but if it is a genuinely new idea there are by definition no references. You are asking them to imagine what you are imagining by hinting at it in a foreign tongue.  In addition to being a work in its own right, "Audium Model" is also the first step in the aesthetic research for "Audium" and a realization of its fundamental concepts. It consists of a special double phone booth for two people: two rooms, each with one transparent wall with a door in it. Inside each room is a telephone handset mounted on the wall. To model the conditions of a phone call, the booths are arranged so that the occupants can't see each other. The handsets connect them through a third party - the computer system which comprises the work. The aural result of the sound activities between these three parties emanates from speakers outside the booths. So we have the elements of "Audium": the telephone hand-sets represent any telephone, the electronic system is the moderator, and the speakers outside the booths are the broadcast. 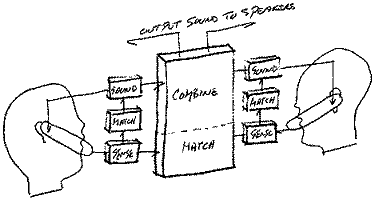 The electronic system has two roles. One, it engages in a sound dialogue with each of the occupants of the booths and, two, it acts as the instrument which they play on with their voices. This general form of the work has been fixed. I am now in the process of research which will define the rest of it. The block diagram shows the current state of my ideas about the flows of information and sound. You can see that there is an arrow going back from the work into the ear piece of each person's telephone. This is a new idea for the broadcast works - what I am calling an active score - a dialogue between each person and the work. When we speak we have to listen constantly to the sound we are making and adjust our sound-producing muscles so that it matches the phoneme we are trying to pronounce. If we could not hear ourselves, we could no longer speak accurately; we need this constant feedback even though we have been doing it all our lives. I want to add another layer to this feedback. In spite of science's general aversion to studying the language of inflection, there have been a number researchers who have been interested in the question over the last fifty years. Most have been motivated by a quest to quantify emotion, many with the goals of lie detection and business advantage. As a result of all this, the basic acoustic parameters of intonation have emerged. Quantifying their meaning is another question, but of course that is not what I am interested in doing here. The dialogue between the work and the persons in the booths will be in the language of inflection. The work will 'recognize' a person's vocal phrases by inflection and continually respond by generating sound for his ear piece - a special sound feed-back which is built for each person as he vocalizes. I hope it will be a means of breaking away from the stereotyped ideas of what music is and can guide them out of their self-consciousness and past their preconceptions. The acoustic parameters of inflection are of course patterns of fundamental frequency, amplitude, formant and spectrum. So far I have built and am working with a system which can extract some of these parameters in real time from two people simultaneously. I have also implemented a neural network algorithm which allows one-pass categorization and mapping of analog vectors also in real time.1 It can be used to generalize - to make decisions through inference and extrapolation - and it learns immediately. It is not like a back propagation neural net which has to be taught for a few hours; it only takes this one ten milliseconds to find or learn a category. These are the components I will use to build the work's sense of each person's vocal activity and its sound response for the active scores. The other part of the work, again an instrument that can be played by the voice, will generate the work's output sound. It will also use this sense of the person's vocal activity to adjust itself while being played. Currently I am experimenting with some imaginary string spaces - digital implementations of six separate strings whose characteristics can be modulated in real time. Because I have all this information about frequency and amplitude coming in, I can not only apply a voice-sound to activate the string; but I can also get the string to listen and respond to what it is being touched with. I like the idea of being able to pluck or stroke a listening string with your tongue from a distance of 10,000 miles over a telephone. Of course the realization of one "Audium Model" does not model the multilingual nature of "Audium". After the first realization the next step would be to implement several 'Audium Models' in different language groups and interconnect them; this is fairly straight forward once the first "Audium Model" is made. This network of interconnected "Audium Models", as an international installation, is the real model of 'Audium' itself. An additional idea for these broadcast works which I became convinced of after "Radio Net" and I hope will be implemented with 'Audium' is the one of a radio installation. All of the works so far have been radio events, because that is the nature of radio in most people's minds: it has events - radio shows. But one could also make a radio installation. Although a radio event certainly gets attention and encourages people to enter into it, at the same time it makes it difficult to do so as it generates congestion. In "Radio Net", 10,000 won and got their calls through. This probably means that 100,000 tried and weren't successful. There is no way to install enough lines to respond to a call-in request of this kind over the radio; the more lines you add the more people are encouraged to call in. The radio event also discourages the development of a group dialogue; everyone knows they have only a certain amount of time and wants to get their say in. But if it's always there you can call in at any time, and you can stay in as long as you want; it allows a natural long term evolution of this new kind of sound dialogue. It becomes an entity - a virtual place. Do I sense shivers of panic running up the spine of radio administration? Of course it is very expensive to run a radio station, and to dedicate it to one idea is unheard of. Or is it?In fact many radio stations are dedicated to one idea - rock, news, sports, etc. "Audium" is another idea of programming; and one hopes its live and unpredictable nature, its continuous evolution, and its international character will combine to make it quite a bit more interesting than many others. I hear them whispering "But the band is so crowded; there aren't enough frequencies to allow another station for such a strange idea". Right now the AM band and many of its transmitters are being abandoned - deserted for the world of FM. "Audium" could live quite happily in all that empty territory, emanating from a few of those unwanted transmitters. It would be considerably less expensive than other forms of programming. The major cost of a radio station is not the broadcasting equipment, nor the electricity to run it. It is the making of radio shows. "Audium" doesn't require staff; it is simply an electronic system with one side connected to the phone network and the other to the transmitter. 'Audium' programs itself, or more accurately it is programmed by the people who will use it. |
[TOP]